Welcome to Laserchicken’s documentation!¶
Laserchicken is a user-extendable, cross-platform Python tool for extracting statistical properties (features in machine learning jargon) of flexibly defined subsets of point cloud data.
User manual¶
Laserchicken processes point clouds from Airborne Laser Scanning in LAS/LAZ format, and normalizes, and filters the points, finds neighbors for targeted points and calculates features.
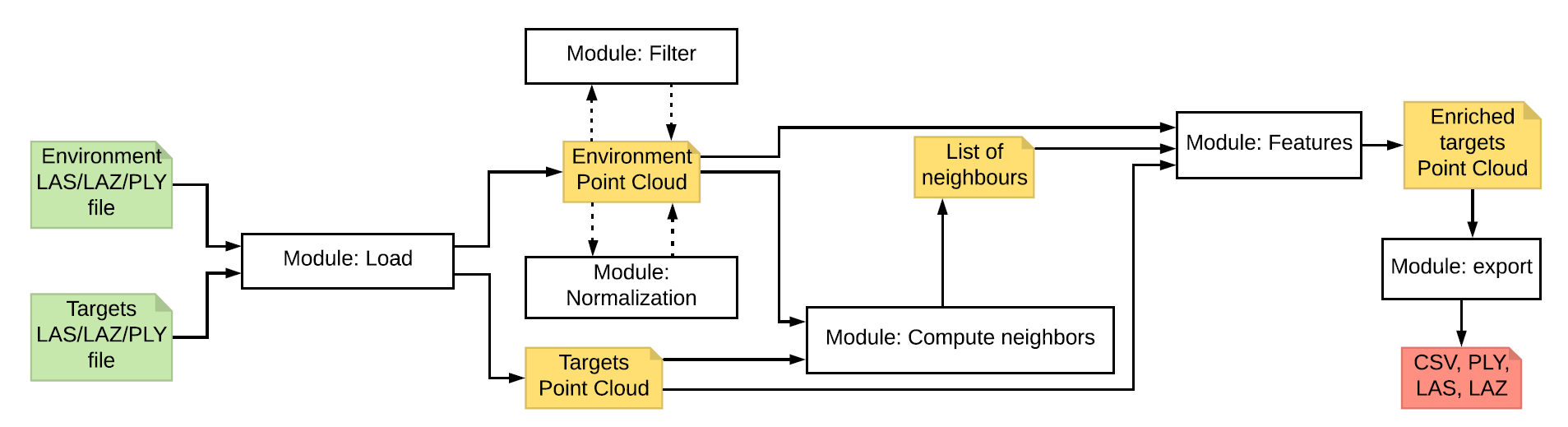
The figure shows the default workflow for which Laserchicken was intended. In short, a point cloud is loaded from a LAS or LAZ or PLY file. After this, points can be filtered by various criteria, and the height can be normalized. A point cloud of targets are loaded. See below a description of what is the concept of a target point. For every target point, neighbors will be computed. Based on the list of neighbors, features are extracted that effectively describe the neighborhood of each target point.
Environment and target point cloud¶
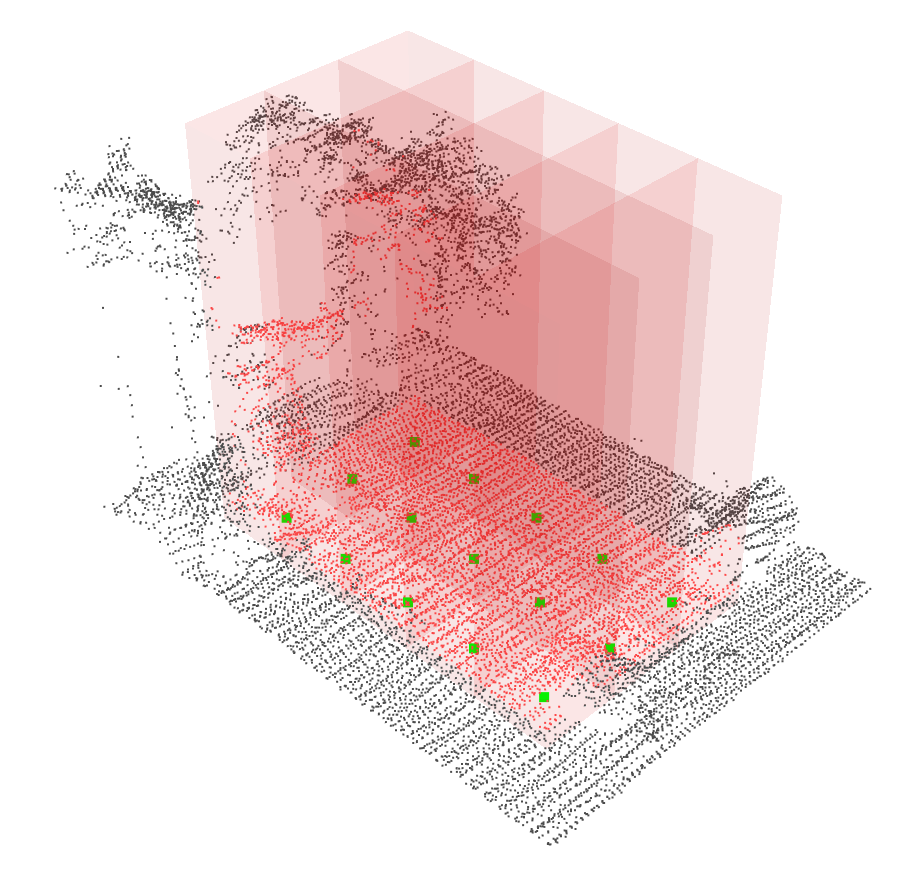
In Laserchicken, the LiDAR dataset is referred to as the environment point cloud (EPC), and the subsets of points over which a metric is to be calculated are referred to as neighborhoods. Each neighborhood is defined by a target volume and a target point (e.g. a cube of a certain size and its centroid, respectively), with all points enclosed in the volume constituting the neighborhood.
See below an illustration of a target point cloud (green points) representing the centroids of a regular grid cell, and the neighborhoods (red points) defined by a square infinite cell target volume (red columns). Features are calculated over the neighborhood of each target point and then associated with the target point, thus forming the enriched target point cloud (eTPC). Points that are not included in the neighborhoods are shown in in black.
Four volume definitions are implemented: an infinite square cell, an infinite cylinder, a cube and a sphere.




All target points together form the target point cloud (TPC). The TPC can be freely defined by the user, and can be for instance identical to the environment point cloud or alternatively a regular grid as illustrated above. Features are calculated over the list of neighborhoods, with the feature values being associated with each neighborhood’s defining target point, thus forming the enriched target point cloud (eTPC).
Modules¶
Each module from the workflow is described below and an example of its usage is given. If you need more examples, be sure to have a look of the unit tests in the Laserchicken’s source code.
Load¶
The load module provides functionality to load point cloud datasets provided in ASPRS LAS/LAZ, or in PLY format, and is used for both input point clouds. In conjunction with the PDAL library (https://pdal.io/), this provides access to a comprehensive range of point cloud data formats.
Example from the tutorial notebook:
from laserchicken import load
point_cloud = load('testdata/AHN3.las')
Normalize¶
A number of features require the normalized height above ground as input. Laserchicken provides the option of internally constructing a digital terrain model (DTM) and deriving this quantity. To this end, the EPC is divided into small cells 1m or 2.5m squared). The lowest point in each cell is taken as the height of the DTM. Each point in the cell is then assigned a normalized height with respect to the derived DTM height. This results in strictly positive heights and smooths variations in elevation on scales larger than the cell size. The normalized EPC can be used directly in further analysis, or serialized to disk.
Example from the tutorial notebook:
from laserchicken.normalize import normalize
normalize(point_cloud)
Filter¶
Laserchicken provides the option of filtering the EPC prior to extracting features. Points may be filtered on the value of a single attribute relative to a specified threshold (e.g. above a certain normalized height above ground), or on specific values of their attributes (e.g. LAS standard classification). It is also possible to filter with (geo-)spatial layers such as polygons (e.g. regions of interest, land cover types), i.e. selectively including or excluding points.
Example of spatial filtering from the tutorial notebook:
from laserchicken.filter import select_polygon
polygon = "POLYGON(( 131963.984125 549718.375000," + \
" 132000.000125 549718.375000," + \
" 132000.000125 549797.063000," + \
" 131963.984125 549797.063000," + \
" 131963.984125 549718.375000))"
point_cloud = select_polygon(point_cloud, polygon)
Example of applying a filter on the theshold of an attribute:
from laserchicken.filter import select_above, select_below
points_below_1_meter = select_below(point_cloud, 'normalized_height', 1)
points_above_1_meter = select_above(point_cloud, 'normalized_height', 1)
Compute neighbors¶
The Compute neighbors module constructs the neighborhoods as defined by the TPC and target volume by identifying the points in the EPC which reside in the specified volume centered on the target points, returning each as a list of indices to the EPC. This essential step of computing neighboring points for large samples of points is computationally expensive. Laserchicken uses the optimized ckDtree class (kdTrees are a space-partitioning data structure) provided by the scipy library to organize both the EPC and TPC in kdTrees in an initial step prior to the computation of neighbors, subsequently accelerating the process of computing neighbors by using the indices of the points with respect to the kDtrees.
Example from the tutorial notebook:
from laserchicken import compute_neighborhoods
from laserchicken import build_volume
targets = point_cloud
volume = build_volume('sphere', radius=5)
neighborhoods = compute_neighborhoods(point_cloud, targets, volume)
Note that in the above example, neighborhoods is a generator and can only be iterated once. If you would want to do multiple calculations without recalculating the neighbors, you can copy the neighborhoods to a list. This is not done by default because neighborhoods can quickly grow quite large so that available RAM unnecessarily becomes the bottle neck.
Features¶
Feature extraction requires the EPC, the TPC, the computed list of neighborhoods, and a list of requested features as input. For each target point it selects the points of the associated neighborhood and calculates a vector of the requested features over these. This feature vector is appended to the target point, thus defining the eTPC.
Currently, a number of features are implemented, including percentiles of the height distribution and eigenvectors. Computationally expensive calculations requiring multi-dimensional linear algebraic operations (e.g. eigenvectors and eigenvalues) have been vectorized using the einsum function of the numpy library to optimize performance. Their implementation can serve as a template for new features requiring similar operations.
Example from the tutorial notebook:
from laserchicken import compute_features
compute_features(point_cloud, neighborhoods, targets, ['std_z','mean_z','slope'], volume)
Features can be parameterized. If you need different parameters than their defaults you need to register them with these prior to using them.
Example of adding a few parameterized band ratio features on different attributes:
from laserchicken import register_new_feature_extractor
from laserchicken.feature_extractor.band_ratio_feature_extractor import BandRatioFeatureExtractor
register_new_feature_extractor(BandRatioFeatureExtractor(None,1,data_key='normalized_height'))
register_new_feature_extractor(BandRatioFeatureExtractor(1,2,data_key='normalized_height'))
register_new_feature_extractor(BandRatioFeatureExtractor(2,None,data_key='normalized_height'))
register_new_feature_extractor(BandRatioFeatureExtractor(None,0,data_key='z'))
The currently registered features can be listed as follows:
from laserchicken.feature_extractor import list_feature_names
sorted(list_feature_names())
Which outputs something like:
['band_ratio_1<normalized_height<2',
'band_ratio_2<normalized_height',
'band_ratio_2<normalized_height<3',
'band_ratio_3<normalized_height',
'band_ratio_normalized_height<1',
'band_ratio_z<0',
'coeff_var_norm_z',
'coeff_var_z',
'density_absolute_mean_norm_z',
'density_absolute_mean_z',
'echo_ratio',
'eigenv_1',
'eigenv_2',
'eigenv_3',
'entropy_norm_z',
'entropy_z',
'kurto_norm_z',
'kurto_z',
'max_norm_z',
'max_z',
'mean_norm_z',
'mean_z',
'median_norm_z',
'median_z',
'min_norm_z',
'min_z',
'normal_vector_1',
'normal_vector_2',
'normal_vector_3',
'perc_100_normalized_height',
'perc_100_z',
'perc_10_normalized_height',
'perc_10_z',
...
'perc_99_normalized_height',
'perc_99_z',
'perc_9_normalized_height',
'perc_9_z',
'point_density',
'pulse_penetration_ratio',
'range_norm_z',
'range_z',
'sigma_z',
'skew_norm_z',
'skew_z',
'slope',
'std_norm_z',
'std_z',
'var_norm_z',
'var_z']
The following table includes the list of all implemented features:
Feature name |
Formal description |
Example of use |
Refs. |
|---|---|---|---|
Point density ( |
\(N/A\) where \(S\) is the neighborhood target volume (area) for finite (infinite) cells |
Point cloud spatial distribution |
|
Pulse penetration ratio ( |
\(N_{\mathrm{ground}}/N_{\mathrm{tot}}\) |
Tree species classification |
[1] |
Echo ratio ( |
\(N_{\mathrm{sphere}}/N_{\mathrm{cylinder}}\) |
Roof detection |
[2] |
Skewness ( |
\(1/\sigma^3 \cdot \sum{(Z_i - \bar{Z})^3/N}\) |
Vegetation, ground, and roof classification and detection |
[3] |
Kurtosis ( |
\(1/\sigma^4 \cdot \sum{(Z_i - \bar{Z})^4/N}\) |
Vegetation, ground, and roof classification and detection |
[3] |
\(\sqrt{\sum{(Z_i - \bar{Z})^2/(N - 1)}}\) |
Classification of reed within wetland |
[4] |
|
Variance ( |
\(\sum{(Z_i - \bar{Z})^2/(N - 1)}\) |
Classification of reed within wetland |
[4] |
Sigma Z ( |
\(\sqrt{\sum{(R_i - \bar{R})^2/(N - 1)}}\) where \(R_i\) is the residual after plane fitting |
[4] |
|
\(Z_{\mathrm{min}}\) |
Simple digital terrain model in wetlands |
[4] |
|
\(Z_{\mathrm{max}}\) |
Height and structure of forests |
[5] |
|
\(\sum{Z_{i}}/N\) |
Height and structure of forests |
[5] |
|
Median Z ( |
\(Z_{\mathrm{median}}\) |
Height and structure of forests |
[5] |
\(|Z_{\mathrm{max}} - Z_{\mathrm{min}}|\) |
Height and structure of forests |
[5] |
|
Percentiles Z ( |
Height of every \(10^{\mathrm{th}}\) percentile. |
Height and structure of forests |
[5] |
Eigenvalues ( |
\(\lambda_1, \lambda_2, \lambda_3 ` , with :math:`|\lambda_1| \ge |\lambda_2| \ge |\lambda_3|\) |
Classification of urban objects |
[6] |
Normal vector ( |
eigen vector \(\vec{v}_3\) |
Roof detection |
[7] |
Slope ( |
\(\tan(\mathrm{arccos}(\vec{v}_3\cdot\vec{k}))\) , where \(\vec{k} = [0,0,1]^T\) |
Planar surface detection |
[8] |
Entropy Z ( |
\(-\sum_{i}{P_i \cdot \mathrm{log}_2{P_i}}\), with \(P_i = N_i/\sum_{j}{N_j}\) and \(N_i\) points in bin \(i\) |
Foliage height diversity |
[9] |
\(\frac{1}{\bar{Z}} \cdot \sqrt{\sum{\frac{(Z_i - \bar{Z})^2}{N - 1}}}\) |
Urban tree species classification |
[10] |
|
Density absolute mean ( |
\(100 \cdot \sum [Z_i > \bar{Z}]/N\) |
Urban tree species classification |
[10] |
Band ratio ( |
\(N_{Z_1<Z<Z_2}/N_{\mathrm{tot}}\) where \(Z_1\) and \(Z_2\) are user-provided values |
Height and structure of forests |
Also available for the normalized height (e.g. mean_normalized_height)
Fully customizable in variable and range
Below is an example. The figure visualizes the slope feature for a small neighborhood size. We used the same target point cloud as the environment point cloud. The image was generated using mayavi plotting software (https://docs.enthought.com/mayavi/mayavi/).

Export¶
Laserchicken can write to PLY or LAS/LAZ format for further analysis with the user’s choice of software. The PLY format is preferred, as it is flexibly extendable and is the only format Laserchicken will write provenance data to. It is also a widely supported point cloud format.
Example from the tutorial notebook:
from laserchicken import export
export(point_cloud, 'my_output.ply')
Xiaowei Yu, Paula Litkey, Juha Hyyppä, Markus Holopainen, and Mikko Vastaranta. Assessment of low density full-waveform airborne laser scanning for individual tree detection and tree species classification. Forests, 5(5):1011–1031, 2014. doi:10.3390/f5051011.
B. Höfle, W. Mücke, M. Dutter, M. Rutzinger, and P. Dorninger. Detection of building regions using airborne lidar : a new combination of raster and point cloud based gis methods. In A. Car, G. Griesebner, and J. Strobl, editors, Geospatial crossroads \@ GI_Forum '09 : proceedings of the geoinformatics forum Salzburg, : Geoinformatics on stage, July 7 - 10, 2009., pages 66–75. Wichmann Verlag, Germany, 2009.
Fabio Crosilla, Dimitri Macorig, Marco Scaioni, Ivano Sebastianutti, and Domenico Visintini. Lidar data filtering and classification by skewness and kurtosis iterative analysis of multiple point cloud data categories. Applied Geomatics, 5(3):225–240, Sep 2013. URL: https://doi.org/10.1007/s12518-013-0113-9, doi:10.1007/s12518-013-0113-9.
András Zlinszky, Werner Mücke, Hubert Lehner, Christian Briese, and Norbert Pfeifer. Categorizing wetland vegetation by airborne laser scanning on lake balaton and kis-balaton, hungary. Remote Sensing, 4(6):1617–1650, 2012. URL: https://www.mdpi.com/2072-4292/4/6/1617, doi:10.3390/rs4061617.
Erik Næsset. Predicting forest stand characteristics with airborne scanning laser using a practical two-stage procedure and field data. Remote Sensing of Environment, 80(1):88 – 99, 2002. URL: http://www.sciencedirect.com/science/article/pii/ S0034425701002905, doi:https://doi.org/10.1016/S0034-4257(01)00290-5.
Martin Weinmann, Michael Weinmann, Clément Mallet, and Mathieu Brédif. A classification-segmentation framework for the detection of individual trees in dense mms point cloud data acquired in urban areas. Remote Sensing, 9(3):277, Mar 2017. URL: http://dx.doi.org/10.3390/rs9030277, doi:10.3390/rs9030277.
Peter Dorninger and Norbert Pfeifer. A comprehensive automated 3d approach for building extraction, reconstruction, and regularization from airborne laser scanning point clouds. Sensors, 8(11):7323–7343, 2008. URL: https://www.mdpi.com/1424-8220/8/11/7323, doi:10.3390/s8117323.
Balázs Székely, Zsófia Koma, Dávid Karátson, Peter Dorninger, Gerhard Wörner, Melanie Brandmeier, and Clemens Nothegger. Automated recognition of quasi-planar ignimbrite sheets as paleosurfaces via robust segmentation of digital elevation models: an example from the central andes. Earth Surface Processes and Landforms, 39(10):1386–1399, 2014. URL: https://onlinelibrary.wiley.com/doi/abs/10.1002/esp.3606, doi:10.1002/esp.3606.
Soyeon Bae, Bjoern Reineking, Michael Ewald, and Joerg Mueller. Comparison of airborne lidar, aerial photography, and field surveys to model the habitat suitability of a cryptic forest species – the hazel grouse. International Journal of Remote Sensing, 35(17):6469–6489, 2014. URL: https://doi.org/10.1080/01431161.2014.955145, doi:10.1080/01431161.2014.955145.
Zsófia Koma, K Koenig, and Bernhard Höfle. Urban tree classification using full-waveform airborne laser scanning. ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, III-3:185–192, 06 2016. doi:10.5194/isprs-annals-III-3-185-2016.